Mochi 1 Preview: Open Source Video Generation with High-Fidelity Motion
Experience state-of-the-art video generation with exceptional motion quality and prompt adherence, powered by our 10B parameter AsymmDiT architecture
Try on Playground
Featured Examples
Explore groundbreaking open-source video generation powered by our novel Asymmetric Diffusion Transformer
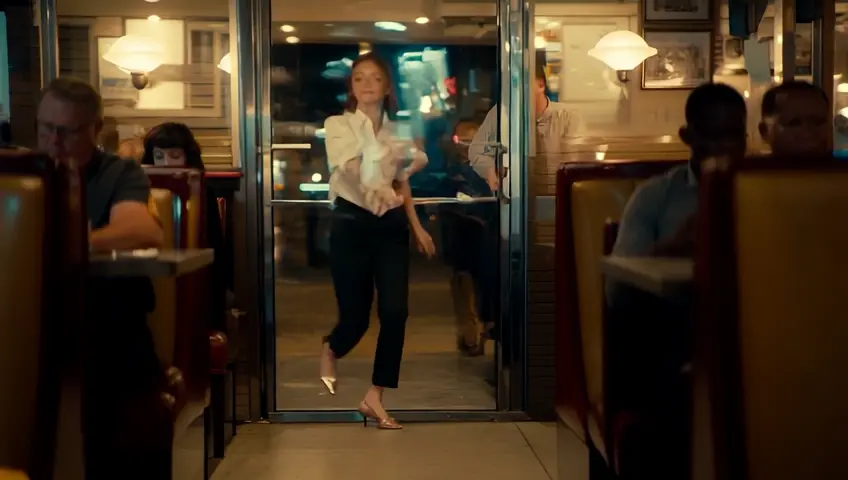
A static shot of a diner at night. The door swings open and a young blind lady enters...

A static shot of a diverse group of people standing on top of a high hill, overlooking a sprawling, vibrant cityscape...

An FPV drone swoops through the colorful coral-lined street of an underwater neighborhood...

A wide shot of the vast expanse of outer space, with planets and stars twinkling in the distance...

A close-up shot of a majestic horse's eye, with a glossy brown coat reflecting the light...

A static shot of a chubby orange and white cat sitting comfortably on a plush sofa...

A wide shot of a vast, otherworldly desert with a deep blue sky overhead...

A drone shot flies down into the central courtyard of a majestic medieval castle...

A cinematic anamorphic shot of a man walking through a dimly lit, foggy graveyard...

A static shot of actress Daisy Ridley, dressed in a sleek, strapless red gown with black detailing...

A stylish man in a three-piece suit and a gold chain draped across his vest exits a 1940s night club...
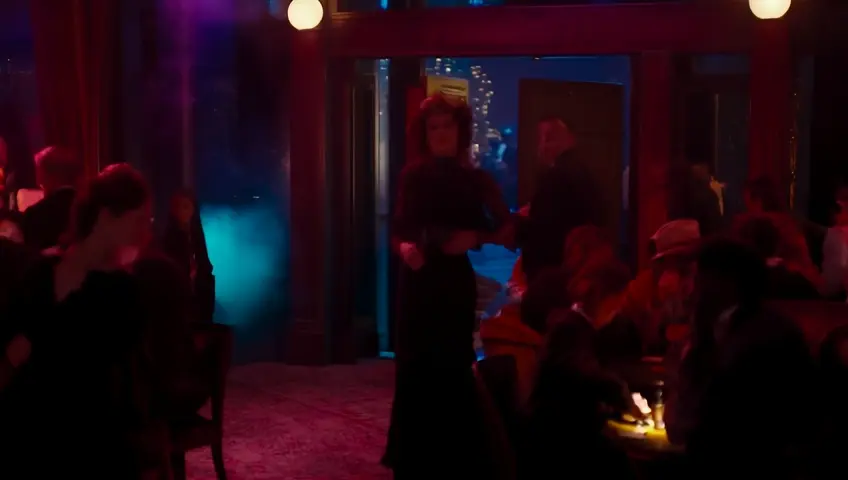
A close-up of a humanoid lemur with a playful face wearing a cyberpunk tactical suit...

A static shot of a young blind lady entering a small diner at night...
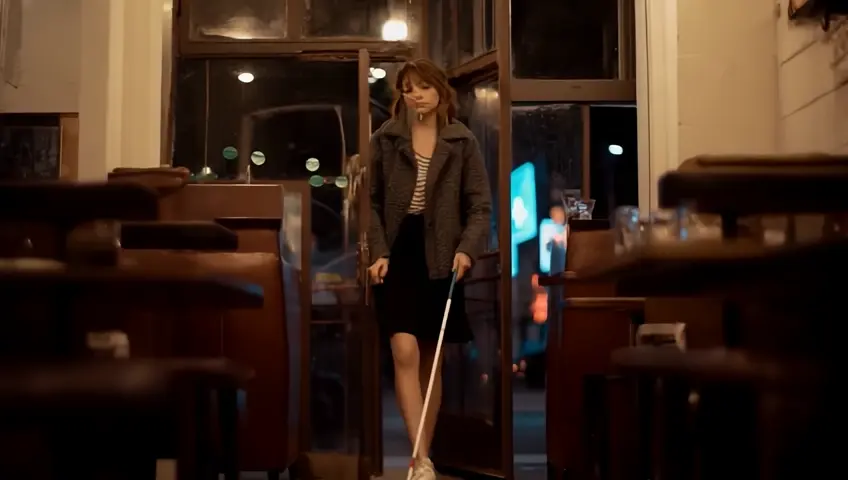
A static shot of a horse's face fills the frame, with the camera focusing on its deep brown eye...

A close-up shot of actress Daisy Ridley in a red dress, with black detailing and sheer sleeves...

A close-up shot of a steaming cup of coffee on a rustic wooden table...

A close-up shot of a smiling child holding a brightly colored spinning top...

A close-up shot of an adorable white, fluffy cat dressed in a vibrant, colorful outfit...

A static shot of a mystical figure dressed in flowing white robes...

A close-up shot of a time portal opening up in the modern city...
State-of-the-Art Video Generation
High-Fidelity Motion
Industry-leading motion quality through our 10B parameter diffusion model with strong prompt adherence in preliminary evaluation
Open Source Architecture
Built on the novel Asymmetric Diffusion Transformer (AsymmDiT) architecture, freely available under Apache 2.0 license
Advanced Compression
Featuring our open-source VAE that causally compresses videos to 128x smaller size with 8x8 spatial and 6x temporal compression
Efficient Processing
Streamlined text processing with single T5-XXL language model and optimized visual reasoning capacity
Multimodal Architecture
Joint attention to text and visual tokens with dedicated MLP layers for each modality and non-square QKV projection
Developer-Friendly
Simple, hackable architecture with comprehensive documentation and community support
Generate Videos with Mochi 1
Setup Environment
Clone the repository and install dependencies using uv package manager
Configure Parameters
Set model directory, CFG scale, and seed values for controlled generation
Generate Content
Run inference through Gradio UI or command line interface
Community Feedback

John Doe
The motion quality and prompt adherence set new standards for open-source video generation.

Alex Smith
The simple, hackable architecture makes it perfect for research and experimentation.

Emily Zhang
Impressive results with the efficient single T5-XXL language model approach.
Frequently Asked Questions
► What makes Mochi 1 unique?
► What are the technical specifications?
► How does the architecture work?
► What are the current limitations?
Join the Open Source Video Generation Revolution
Experience the largest openly released video generative model
Try Mochi 1